






摘要:本文介绍了实时处理平台Storm的入门指南,包括如何搭建和优化实时数据流处理系统。通过Storm平台,可以实现对数据流的实时处理和分析,提高数据处理效率和准确性。本文将为读者提供有关Storm平台的详细指导,帮助读者快速入门并优化实时数据流处理系统的性能。
一、前言
随着大数据时代的到来,实时数据处理变得越来越重要,Storm作为分布式实时计算系统,广泛应用于大数据处理的场景,本指南旨在帮助初学者和进阶用户了解并学会如何在12月13日(或其他时间)搭建和优化Storm实时处理平台,我们将从Storm的基本概念开始,逐步深入,确保每位读者都能从中受益。
二、Storm实时处理平台简介
Storm是一个开源的分布式实时计算系统,用于处理大数据流,它可以水平扩展以处理大量数据,并具有容错性,保证数据的实时处理,Storm适用于各种应用场景,如实时分析、实时机器学习、事件驱动微服务等。
三、搭建Storm实时处理平台步骤
1、环境准备
选择合适的服务器或集群环境,确保有足够的资源运行Storm集群。
安装Java运行环境,因为Storm是基于Java的。
2、下载并安装Storm
访问Storm官网或GitHub页面,下载最新稳定版本的Storm。
解压下载的文件,并按照官方文档进行安装。
3、配置Storm
复制或编辑storm.yaml文件,配置如Zookeeper地址、UI地址等参数。
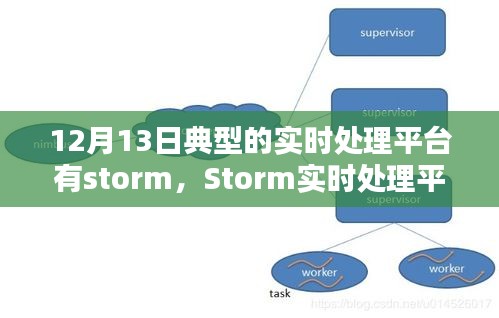
配置Storm的拓扑(Topology),这是数据处理的核心部分。
4、启动Storm集群
首先启动Zookeeper集群(如果还没有的话)。
然后启动Storm的守护进程,包括Nimbus和Supervisor。
通过Storm UI验证集群状态。
5、开发第一个Storm拓扑
学习Storm的编程模型,如Spout和Bolt。
编写第一个简单的拓扑,如一个WordCount程序。
打包并部署拓扑到Storm集群。

6、监控和优化
使用Storm UI监控拓扑的运行状态。
根据性能指标进行优化,如调整并行度、处理速度等。
四、详细步骤及解释
1、环境准备:选择适当的服务器和环境,确保有足够的资源运行Storm集群,这一步是搭建任何大数据处理平台的基础,需要根据实际需求进行配置。
2、下载并安装Storm:访问Storm官网或GitHub页面获取最新版本的Storm安装包,然后按照官方文档进行安装,这一步相对简单,但需要确保Java环境已经安装好。
3、配置Storm:配置Storm的关键在于storm.yaml文件,这里需要设置Zookeeper的地址、UI的地址等参数,还需要配置Storm的拓扑,这是数据处理的核心部分,配置拓扑时需要注意数据的流向和处理逻辑。
4、启动Storm集群:启动Zookeeper集群后,可以启动Storm的守护进程,包括Nimbus和Supervisor,通过Storm UI可以验证集群的状态,确保所有节点正常运行,这一步需要确保每个节点都能正确连接到集群。
5、开发第一个Storm拓扑:学习Storm的编程模型,如Spout和Bolt,然后编写一个简单的拓扑程序,如WordCount,这一步需要理解Storm的基本编程模型和数据处理方式,完成编写后,需要打包并部署到Storm集群进行测试。

6、监控和优化:使用Storm UI监控拓扑的运行状态,包括处理速度、延迟等指标,根据监控结果进行优化,如调整并行度、优化数据处理逻辑等,这一步是确保系统性能的关键,需要根据实际业务需求进行调整。
五、注意事项
在搭建过程中,确保所有节点的网络连通性。
在配置拓扑时,注意数据的流向和处理逻辑的正确性。
在开发拓扑时,遵循良好的编程习惯,保证代码的可读性和可维护性。
在优化过程中,关注性能指标的同时也要考虑系统的稳定性。
六、结语
通过本指南的学习和实践,初学者和进阶用户应该能够成功搭建和优化Storm实时处理平台,希望本指南能对大家有所帮助,如有任何疑问或建议,欢迎交流讨论。
转载请注明来自溜溜的小站,本文标题:《Storm实时处理平台入门指南,搭建并优化实时数据流处理系统指南》
 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...